Open-source multimodal large language models (MLLMs) have shown significant potential in a broad range of multimodal tasks. However, their reasoning capabilities remain constrained by existing instruction-tuning datasets, which were predominately repurposed from academic datasets such as VQA, AI2D, and ChartQA. These datasets target simplistic tasks, and only provide phrase-level answers without any intermediate rationales. To address these challenges, we introduce a \textit{scalable and cost-effective method} to construct a \textit{large-scale multimodal instruction-tuning dataset with rich intermediate rationales designed to elicit CoT reasoning}. Using only open models, we create a dataset containing 12M instruction-response pairs to cover diverse, reasoning-intensive tasks with detailed and faithful rationales. Experiments demonstrate that training MLLMs on this dataset significantly improves reasoning capabilities, achieving state-of-the-art performance on benchmarks such as MathVerse (+8.1%), MMMU-Pro (+7%), and MuirBench (+13.3%). Additionally, the model demonstrates notable improvements of up to 4% on non-reasoning-based benchmarks. Ablation studies further highlight the importance of key components, such as rewriting and self-filtering, in the dataset construction process.

While previous efforts have highlighted the potential of visual instruction tuning, many rely on resource-intensive methods such as human annotations or proprietary models. These approaches limit scalability and accessibility, particularly in open-source contexts. To address these challenges, we introduce a simple, scalable, and cost-effective data generation pipeline that produces 12 million high-quality samples. Our pipeline involves three key steps:
(1) open-source data collection and categorization
(2) task-specific data augmentation and rewriting using open models
(3) quality filtering to remove hallucinated or irrelevant content

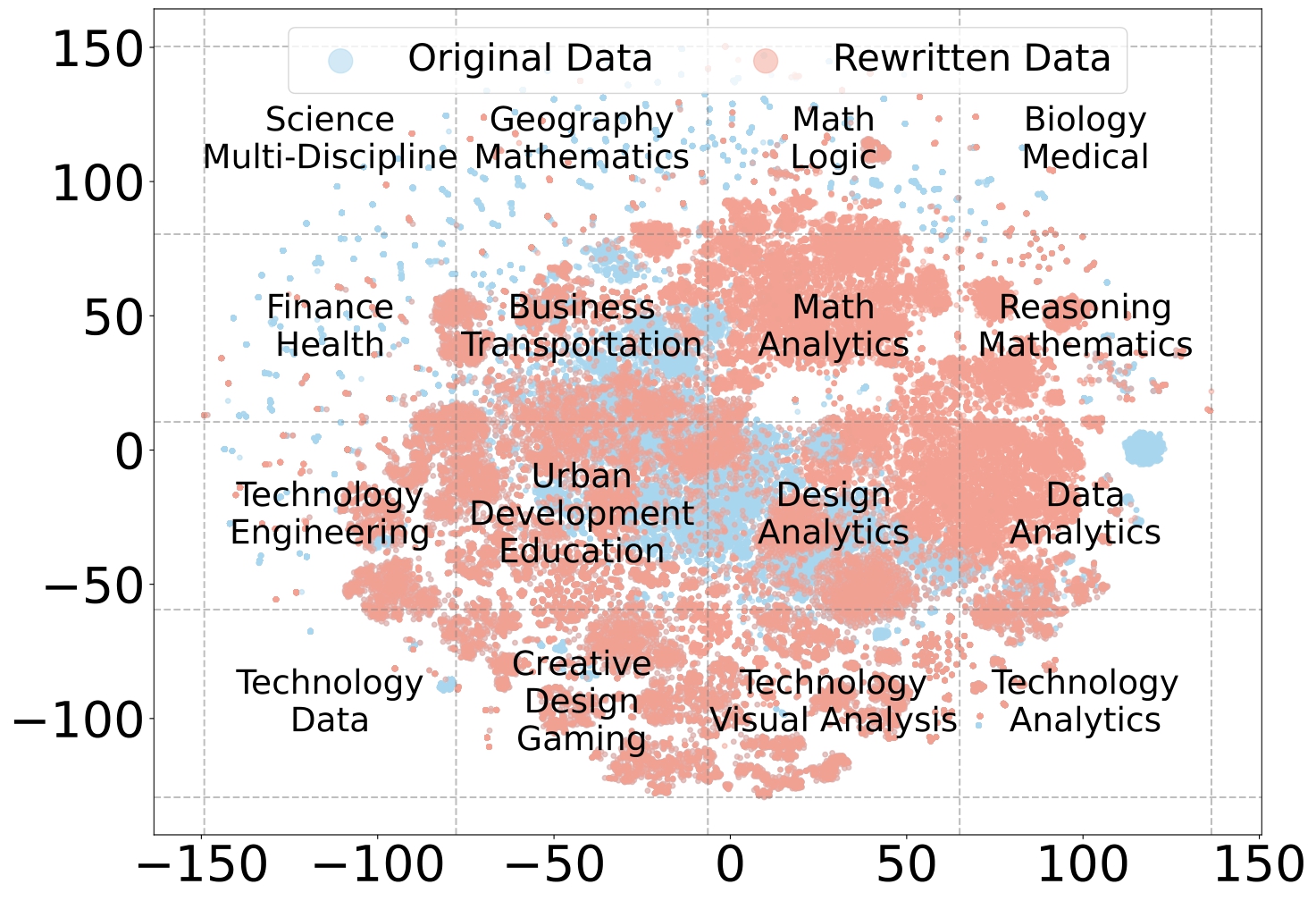
To analyze the distributional differences between the original and rewritten data, we randomly sampled 80,000 examples from the dataset both before and after rewriting and visualized their distributions using t-SNE to project the instructions onto a two-dimensional plot in Figure 3. The resulting figure reveals two key takeaways:
(1) The rewritten data exhibits significant overlap with the original data, indicating that it retains the core characteristics of the original distribution. This ensures that the rewritten data preserves the foundational structure of the dataset.
(2) The rewritten data extends beyond the boundaries of the original distribution, demonstrating that it introduces new dimensions or variations, which shows that rewriting enhances the dataset by broadening its scope while maintaining its original essence.
Based on this observation, during the experimental validation phase, we utilize a mixed dataset consisting of 70% rewritten data and 30% original data to train the model.
To reveal the generality and effectiveness of the model, we comprehensively evaluate it across different scenarios, including single-image, multi-image, and video benchmarks. Detailed results are presented in Table 1, Table 2 and Table 3, respectively. We denote the model checkpoint that completed the single-image stage and one-vision stage as MAmmoTH-VL-8B (SI) and MAmmoTH-VL-8B. We conduct standardized, reproducible evaluations of our model across all 23 benchmarks using LMMs-Eval. To ensure a fair comparison with other MLLMs, we primarily report results from the original papers. When results are unavailable, we onboard the models in LMMs-Eval and evaluate them using consistent settings. All results are reported using greedy decoding and zero-shot settings unless specified.
| Model | Multi-Discipline Knowledge and Mathematical Reasoning | |||||||
|---|---|---|---|---|---|---|---|---|
| MMStar test |
MMMU val |
MMMU-Pro vision |
SeedBench test |
MMBench en-test |
MMVet test |
MathVerse mini-vision |
MathVista testmini |
|
| GPT-4o | 64.7 | 69.1 | 49.7 | 76.2 | 82.1 | 76.2 | 50.2 | 63.8 |
| Gemini-1.5-Pro | 59.1 | 65.8 | 44.4 | 76.0 | 73.9 | 64.0 | - | 63.9 |
| Claude-3.5-Sonnet | 62.2 | 68.3 | 48.0 | 72.2 | 79.7 | 75.4 | - | 67.7 |
| InternVL2-LLaMa3-76B | 67.1 | 58.2 | 38.0 | 77.6 | 86.5 | 64.4 | - | 65.5 |
| Qwen2-VL-72B-Ins | 68.6 | 64.5 | 37.1 | 77.9 | 86.9 | 73.9 | 37.3 | 70.5 |
| LLaVA-OV-72B (SI) | 65.2 | 57.4 | 26.0 | 77.6 | 86.6 | 60.0 | 37.7 | 66.5 |
| LLaVA-OV-72B | 66.1 | 56.8 | 24.0 | 78.0 | 85.9 | 63.7 | 39.1 | 67.5 |
| MiniCPM-V-2.6-7B | 57.5 | 49.8 | 21.7 | 74.0 | 81.5 | 60.0 | - | 60.6 |
| InternLM-XComp-2.5-7B | 59.9 | 42.9 | - | 75.4 | 74.4 | 51.7 | 20.0 | 59.6 |
| Llama-3.2-11B-Vision-Ins | 49.8 | 50.7 | 23.7 | 72.7 | 73.2 | 57.6 | 23.6 | 51.5 |
| InternVL-2-8B | 59.4 | 49.3 | 25.4 | 76.0 | 81.7 | 60.0 | 27.5 | 58.3 |
| Qwen2-VL-7B-Ins | 60.7 | 52.1 | 26.9 | 74.3 | 83.0 | 62.0 | 28.2 | 58.2 |
| Cambrian-1-8B | - | 42.7 | 14.7 | 73.3 | 74.6 | 48 | - | 49.0 |
| Llava-CoT-11B | 57.6 | 48.9 | 18.5 | 75.2 | 75.0 | 60.3 | 24.2 | 54.8 |
| Molmo-7B-D | 50.5 | 45.3 | 18.9 | 74.1 | 73.6 | 58.0 | 21.5 | 51.6 |
| LLaVA-OV-7B (SI) | 60.9 | 47.3 | 16.8 | 74.8 | 80.5 | 58.8 | 26.9 | 56.1 |
| LLaVA-OV-7B | 61.7 | 48.8 | 18.7 | 75.4 | 80.8 | 58.6 | 26.2 | 63.2 |
| MAmmoTH-VL-8B (SI) | 55.4 | 49.4 | 26.0 | 73.3 | 83.0 | 60.6 | 35.0 | 67.6 |
| MAmmoTH-VL-8B | 63.0 | 50.8 | 25.3 | 76.0 | 83.4 | 62.3 | 34.2 | 67.6 |
| ∆ Over Best Open-Source (~10B Scale) |
+1.3 | +1.9 | +7.1 | +0.6 | +2.6 | +2.0 | +8.1 | +4.4 |
| Model | Chart & Doc Understanding | Multimodal Interactions & Preferences | ||||||
|---|---|---|---|---|---|---|---|---|
| AI2D test |
ChartQA test |
InfoVQA test |
DocVQA test |
RealWorldQA test |
WildVision 0617 |
L-Wilder small |
||
| GPT-4o | 94.2 | 85.7 | 79.2 | 92.8 | 76.5 | 89.4 | 85.9 | |
| Gemini-1.5-Pro | 94.4 | 87.2 | 81.0 | 93.1 | 70.4 | - | - | |
| Claude-3.5-Sonnet | 94.7 | 90.8 | 49.7 | 95.2 | 59.9 | 50.0 | 83.1 | |
| InternVL2-LLaMa3-76B | 88.4 | 88.4 | 82.0 | 94.1 | 72.7 | - | - | |
| Qwen2-VL-72B-Ins | 88.1 | 88.3 | 84.5 | 96.5 | 77.8 | - | - | |
| LLaVA-OV-72B (SI) | 85.1 | 84.9 | 74.6 | 91.8 | 73.8 | 49.5 | 72.9 | |
| LLaVA-OV-72B | 85.6 | 83.7 | 74.9 | 91.3 | 71.9 | 52.3 | 72.0 | |
| MiniCPM-V-2.6-7B | 82.1 | 82.4 | - | 90.8 | 65.0 | 11.7 | - | |
| InternLM-XComp-2.5-7B | 81.5 | 82.2 | 70.0 | 90.9 | 67.8 | - | 61.4 | |
| Llama-3.2-11B-Vision-Ins | 77.3 | 83.4 | 65.0 | 88.4 | 63.3 | 49.7 | 62.0 | |
| InternVL-2-8B | 83.8 | 83.3 | 74.8 | 91.6 | 64.4 | 51.5 | 62.5 | |
| Qwen2-VL-7B-Ins | 83.0 | 83.0 | 76.5 | 94.5 | 70.1 | 44 | 66.3 | |
| Cambrian-1-8B | 73.3 | 73.3 | 41.6 | 77.8 | 64.2 | - | - | |
| Llava-CoT-11B | - | 67.0 | 44.8 | - | - | - | 65.3 | |
| Molmo-7B-D | 81.0 | 84.1 | 72.6 | 92.2 | 70.7 | 40 | - | |
| LLaVA-OV-7B (SI) | 81.6 | 78.8 | 65.3 | 86.9 | 65.5 | 39.2 | 69.1 | |
| LLaVA-OV-7B | 81.4 | 80.0 | 68.8 | 87.5 | 66.3 | 53.8 | 67.8 | |
| MAmmoTH-VL-8B (SI) | 83.4 | 85.9 | 74.8 | 93.8 | 71.3 | 51.9 | 71.3 | |
| MAmmoTH-VL-8B | 84.0 | 86.2 | 73.1 | 93.7 | 69.9 | 51.1 | 70.8 | |
| ∆ Over Best Open-Source (~10B Scale) |
+2.4 | +2.1 | +2.2 | +1.6 | +0.6 | -1.9 | +2.2 | |
| Model | Multi-Image and Video | |||||||
|---|---|---|---|---|---|---|---|---|
| MuirBench test |
MEGABench test |
EgoSchema test |
PerceptionTest test |
SeedBench video |
MLVU dev |
MVBench test |
VideoMME w/o subs |
|
| GPT-4o | 68.0 | 54.2 | - | - | - | 64.6 | - | 71.9 |
| GPT-4v | 62.3 | - | - | - | 60.5 | 49.2 | 43.5 | 59.9 |
| LLaVA-OV-72B (SI) | 33.2 | - | 58.6 | 62.3 | 60.9 | 60.9 | 57.1 | 64.8 |
| LLaVA-OV-72B | 54.8 | 33.8 | 62.0 | 66.9 | 62.1 | 66.4 | 59.4 | 66.2 |
| InternVL-2-8B | 59.4 | 27.7 | 54.2 | 57.4 | 54.9 | 30.2 | 66.4 | 54.0 |
| Qwen2-VL-7B-Ins | 41.6 | 36.0 | 66.7 | 62.3 | 55.3 | 58.6 | 67 | 63.3 |
| LLaVA-OV-7B (SI) | 32.7 | 22.1 | 52.9 | 54.9 | 51.1 | 60.2 | 51.2 | 55.0 |
| LLaVA-OV-7B | 41.8 | 23.9 | 60.1 | 57.1 | 56.9 | 64.7 | 56.7 | 58.2 |
| MAmmoTH-VL-8B | 55.1 | 28.2 | 58.5 | 59.3 | 57.1 | 64.7 | 59.1 | 58.8 |
| ∆ Over Best Open-Source (~10B Scale) |
+13.3 | +4.3 | -1.6 | +2.2 | +0.2 | +0 | +2.4 | +0.6 |
As shown in Figure 4, performance is tracked across benchmarks with training dataset size increasing in 2-million-sample intervals. Results are compared to three leading models: Llava-OneVision-7B & 72B and Llava-CoT. The findings demonstrate a positive correlation between training data scale and performance, indicating that diverse instruction data improves the model's ability to handle complex tasks.

To assess the effect of model size on the quality of rewritten data, we conduct experiments using four models trained on a dataset of 500K samples. The first model is trained on the original dataset. The second model use data rewritten by InternVL2-Llama3-76B and Meta-Llama-3-70B-Instruct. The third model is trained on data rewritten by Qwen2-VL-7B-Instruct and Qwen2.5-7B-Instruct. The fourth model is trained on data rewritten by InternVL2-8B and InternLM2.5-7B. Among these, Qwen2.5-72B-Instruct, Qwen2.5-7B-Instruct, and InternLM2.5-7B are employed solely for rewriting caption data, while InternVL2-Llama3-76B, Qwen2-VL-7B-Instruct, and InternVL2-8B are used for data filtering.
As shown in Figure 5, our analysis reveals distinct patterns in model performance across different task categories. For knowledge & reasoning tasks, models trained on data rewritten by smaller models (approximately 7B parameters) achieve performance comparable to those using larger model rewrites. However, the impact of data rewriting varies significantly by task type. For chart and document-related tasks, rewriting with smaller models actually leads to performance degradation, while larger models provide modest improvements. This suggests that sophisticated visual understanding capabilities of larger models are crucial for effectively rewriting such data. In contrast, Multi Interact & Preference tasks demonstrate a clear correlation with model scale, where larger models excel in handling these complex scenarios that demand subtle understanding and nuanced preference modeling.

@article{guo2024mammothvlelicitingmultimodalreasoning,
title={MAmmoTH-VL: Eliciting Multimodal Reasoning with Instruction Tuning at Scale},
author={Jarvis Guo and Tuney Zheng and Yuelin Bai and Bo Li and Yubo Wang and King Zhu and Yizhi Li and Graham Neubig and Wenhu Chen and Xiang Yue},
year={2024},
eprint={2412.05237},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.05237},
}
 MAmmoTH-VL:
MAmmoTH-VL: